由于超算无法连接到网上环境,通过pip 或者conda 的直接下载包的方式失效。以下提供几种方式。主流的方式应该是在本地docker 创建一个镜像,直接在超算运行镜像环境,这种方法是运行环境最稳定的,缺点是docker的安装和学习 需要一些成本,同时docker hub的国内链接受到网络环境影响,很难下载镜像,在2024.11.7我曾试图在超算上下载image自己改环境,在下载到5gb大小的时候失败,应该是超算做了下载文件大小的限制(2025.3更新,可以通过使用终端命令来上传和下载文件,没有文件大小限制)。
本内容仅针对pytorch和JAX环境的超算使用和安装,tensorflow用户可以借鉴使用(因为tensorflow往往要cuda和tf版本一一对应,有些时候可能不是环境安装问题而是版本对应问题),其他大语言模型机器学习包(例如libcuda.so)可能对cuda的版本和cuda driver的版本有要求,请联系管理员更新cuda和cuda driver。
1 使用conda和linux系统离线打包完整conda环境
1.1 使用conda-pack打包完整的conda环境
1.在联网机器上创建环境并打包
首先你需要一个linux系统,并安装配置好conda
在可以联网的机器上,创建并安装完 environment.yml 或 requirements.txt中的依赖包后,使用 conda-pack 打包整个环境:
conda activate my_env
conda install conda-pack
conda-pack -n my_env -o my_env.tar.gz
2.超算解压
在超算上可以在任意地址解压当前上传的环境包
tar -xzf pytorch_env.tar.gz -C /path/to/env/
这里的/path/to/env/指的是自己设的解压地址,你也可以按我的直接在~/pytorch_env
3.云工具jupyterlab中激活环境
此时已经可以在云工具的jupyterlab中通过jupyterlab 的terminal在环境解压后的 bin 目录中使用 source 命令激活环境:
source /path/to/env/bin/activate
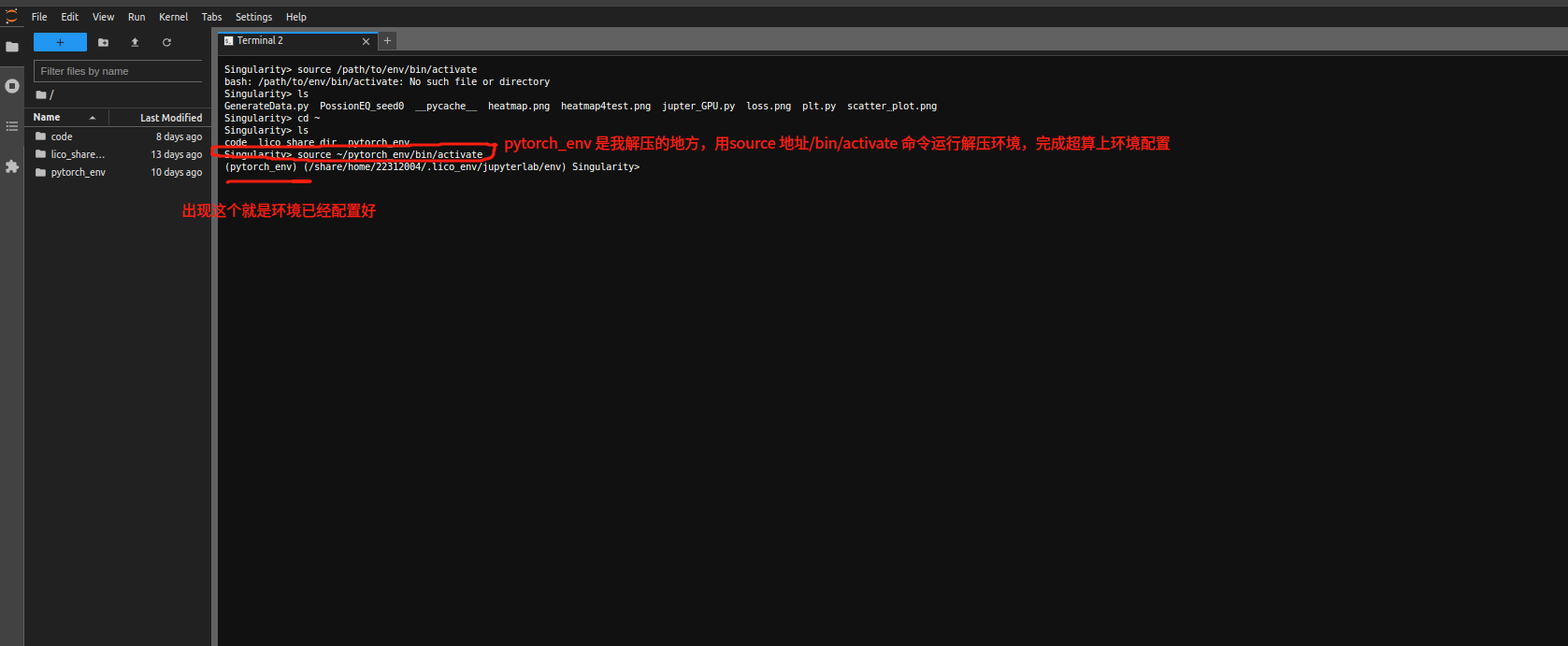
上图的情况说明终端的环境加载成功
如果你使用的是网页版的超算,这个时候已经可以通过python命令运行py文件
python main.py 对于更一般的情况,建议结合vscode和跳板机联合使用
1.2 结合vscode的ssh多级跳跃本地化运行环境管理
这里需要你的ip地址能成功ssh到超算,不能的话找老师申请vpn
在本地电脑上安装vscode和Remote-SSH插件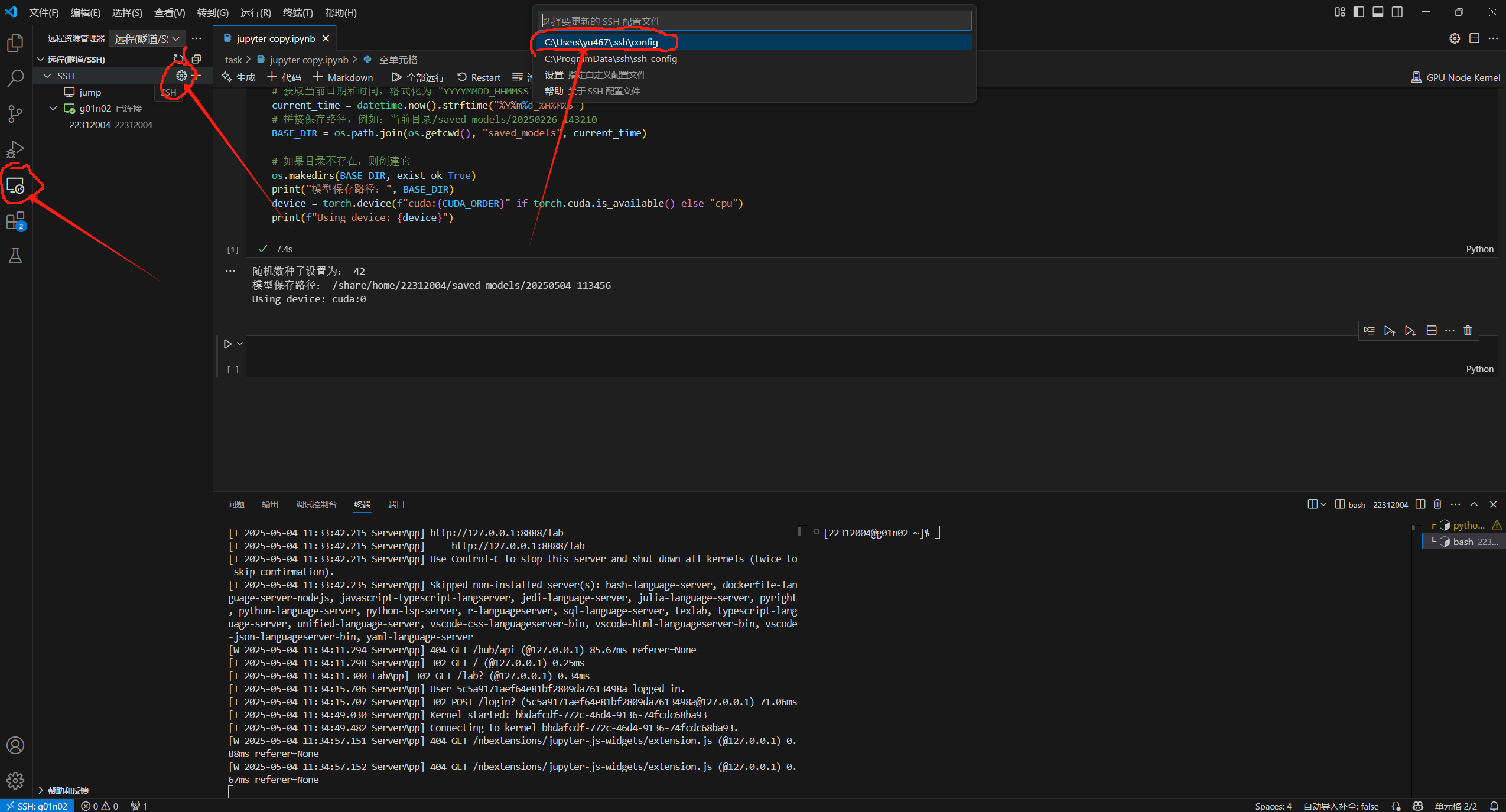
按照图上的形式进入Remote-SSH的配置文件
进入后输入
# 定义跳板机(Jump Host)
Host jump
HostName 集群ip地址
User 账号名
# 定义目标主机gpu1,通过 jump 进行跳转,并做本地端口转发
Host gpu1(任意自定义名)
HostName 目标主机节点名
User 账号名
ProxyJump jump
LocalForward 8888 localhost:8888
目标主机节点名可以通过登录集群后用sinfo查看gpu和cpu资源空闲状态确定
User改成你自己,端口号你输入8888 8889 8890 8899这种都可以
申请交互式计算节点
salloc -p <分区名> -N <节点数> -n <任务数> --cpus-per-task=<cpu数量> --gres=<gpu数量>然后在vscode中点击连接gpu1节点
此时在终端通过以下代码激活环境既可以用python运行py文件
source /path/to/env/bin/activate
如果你已经安装了jupyter notebook
在vscode里安装jupyter插件,你会看到在jupyter文件的右上角可以选择kernel
这个时候已经有了你解压的环境,可以方便的使用jupyter notebook进行代码训练
2 slurm常用命令与使用方法
查看集群分区与节点状态
sinfo查看特定分区空闲节点
申请交互式计算节点
此方法个人感觉为最佳方法
salloc -p <分区名> -N <节点数> -n <任务数> --cpus-per-task=<cpu数量> --gres=<gpu数量>下面这个为申请gpu节点的命令,申请一张gpu卡,同时保证关闭终端不会自动结束任务
(因为目前集群是免费的,太多人占卡了,占卡时长和你的电脑开机时间息息相关。。)
(使用此命令可以无限时长占卡)
salloc --no-kill -p gpu --gres=gpu:1 --job-name=余翔洋 & disownssh 进入节点
ssh <账号名>@<节点名>
ssh <节点名> # 如果已经登录集群提交批处理作业
sbatch <作业脚本文件名>查看作业状态
squeue -u <账号名>停止作业
scancel <作业ID>删除作业
scancel --delete-all <作业ID>3 slurm作业脚本示例
示例一
#!/bin/bash
#SBATCH --job-name='Common_Job_08281120' #定义工作名,任意名称即可
#SBATCH --chdir=/share/home/task/slurm_task #定义脚本工作地址
#SBATCH --partition=gpu_small #定义节点partition,选择gpu或者cpu分区
#SBATCH --nodes=1 #节点数量,gpu的话一般都是1吧
#SBATCH --ntasks-per-node=16 #cpu数量16
#SBATCH --time=0-24:00 #运行时间24h
#SBATCH --gres=gpu:2g.20gb:1 #因为是在small_gpu里,所以--gres=gpu:(抓取)2g.20gb(型号):1(1个)
#SBATCH --mail-type=BEGIN,END,FAIL #运行开始完毕、失败以后发送邮件
#SBATCH --mail-user=yuxiangyang@zju.edu.cn #邮件地址
echo job start time is `date`
echo `hostname`
source ~/jupyter_pytorch_env/bin/activate #激活你的python环境,这里按第一章内容设置
python main.py #运行python文件
echo job end time is `date`示例二
#!/bin/bash
#SBATCH --job-name='Common_Job_08281109'
#SBATCH --chdir=/share/home/22312004/task/slurm_task
#SBATCH --partition=gpu
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=16
#SBATCH --time=0-24:00
#SBATCH --gres=gpu:1 #因为是gpu节点,所以--gres=gpu:1即可,
echo job start time is `date`
echo `hostname`
source ~/jupyter_pytorch_env/bin/activate
python main.py
echo job end time is `date`写好的slurm脚本命名为run.slurm
可以在网页端的General Job里提交
也可以用命令提交
sbatch run.slurm运行成功后终端会显示
Submitted batch job 12345678可以通过squeue -u 账号名查看作业状态
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
12345678 gpu_small Common_Job_08281120 yuxiangyang R 0:01 1 gpu-node[01-02]